Get to know our solution
AWARD WINNING TECHNOLOGY
What make us different?
Our core proprietary technologies use the most advanced AI breakthroughs in cognitive automation, Semantic and Natural Language Processing (NLP), and human-in-the-loop AI-based orchestration to process highly unstructured information with ease, accuracy, and versatility, tied together under a low-to-no code automation platform that abstracts the complexities of AI for line-of-business users.
Capturing data from documents that we’ve never seen?
Unlike most data extraction technologies or OCR engines that capture data based on a heavy set of configuration and templates, DocDigitizer’s data capture engine based on Machine Learning is capable of understanding and capturing data from semantic patterns present in the document and generalizing those patterns across different domains and layouts.
DocDigitizer goes beyond layouts and instead mimics what a human mind does by taking into consideration semantic and structural information and using it to provide data capture with unrivaled precision.
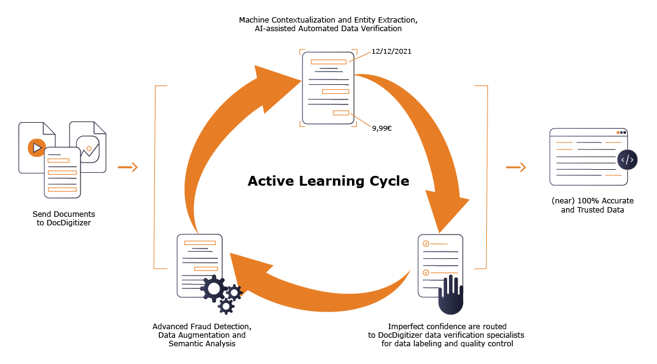
Scalability of Machines, Quality of Humans
DocDigitizer approach ensures the best possible outcomes by combining AI with your human expertise at the right place and time.
We believe machines should proactively learn from humans, and in our platform, the automation basically asks for human guidance. Then, our AI models improve exponentially over time, keeping humans seamlessly in the loop and increasing efficiency and boosting accuracy.
Built to Scale – Skip costly Data Validation processes on your end and get 100% accurate data under very low response times with ease.
Secured – Our Human-In-The-Loop experts operate under very strict security policies, so we can be compliant with GDPR and HIPAA.
Our advanced IDP capabilties
Handwritten extraction – DocDigitizer recognizes and extracts cursive handwriting from paper and electronic documents, far surpassing industry standards at +99% accuracy backed up by SLA, whether they are human resource forms, patient intake, tax, mailroom, or any other.
Signature detection and extraction –DocDigitizer uses deep learning to segment the document into sections that contain either text or visual components, cropping the signature, removing background patterns or stains, and extracting the leftover scribble into a usable format.
Table extraction – We identify where precisely the tables are present in the given input. The input can be of any format, such as Images, PDF documents and sometimes even videos.We use different techniques and algorithms to detect the tables, either by lines or by coordinates. In some cases, we might encounter tables with no borders at all, where we need to opt for different methods.
Support for taxonomies/ontologies –Replace your traditional pair-value output with a rich, dense, and augmented object output allowing developers to leverage or build a myriad of human semantic objects.
Fraud detection – DocDigitizer document fraud detection solution helps you uncover more fraud than ever before by providing, alongside data, a set of key signals of tampering after documentation creation.
Data Anonymization – DocDigitizer is an efficient solution for scaling anonymization and quantitative risk by removing or encrypting personally identifiable data from your documents.