Near 100% Accuracy:
How We Do It
Only (near) 100% Accuracy is good enough!
Data extraction is not an accuracy game. A Bank can’t survive with having a mistake in extracting data from documents in “just” 20% of the times that lead to a wrong KYC or loan approval process. Also the Bank can’t survive with 10%, 1% or even 0.1%. The business and reputational risks are too high.
OCR and other Cognitive Data capture solutions extensively talk about accuracy rate. But that is a flawed discussion. What those providers are doing is actually transferring the burden and responsibility of data curation to the customer.
DocDigitizer not only guarantees near 100% accuracy but also we back that through SLAs in our contracts.
Why and How DocDigitizer can claim (near) 100% accuracy?
Instead of shifting the burden to the customer, we acknowledge that you cannot live without near 100% accuracy and that managing the entire data curation and revision is a wanting task. You have not only to manage technology but also and most important to manage the revision team. You have to manage demands peaks, off time, upscale and downscale.
Actually, Cognitive Data Capture is still far away from a full AI / ML 100% accurate data extraction. We like to compare it with the state of the art of self-driving. It works kind of well in very well behaved scenarios. The problem is, unlike roads and cars that are stable for decades, documents formats and the types of information in documents are actually growing fast.
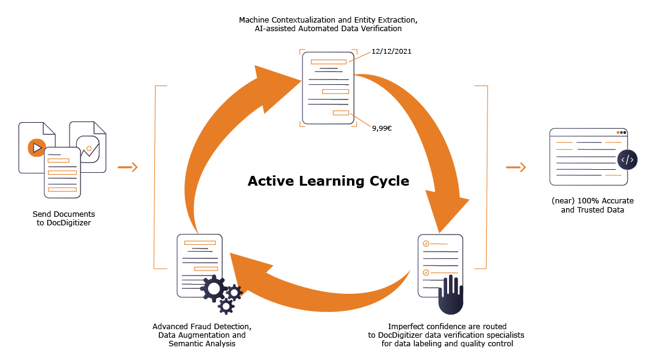
The figure below shows our process. We run proprietary AI / ML algorithms to extract data. After that we leverage our human-in-the-loop team of curate and edit information. Humans are a core part of the process and they are required for the corner cases that still technology doesn’t solve.